For the past few years, the AI compute story has been focusing on GPUs. That story needs a major overhaul. As the main user of AI becomes AI itself, the workloads that will define the next phase of growth look nothing like the workloads GPUs were designed for. They look, with uncanny resemblance, like the workloads CPUs have always been best at.
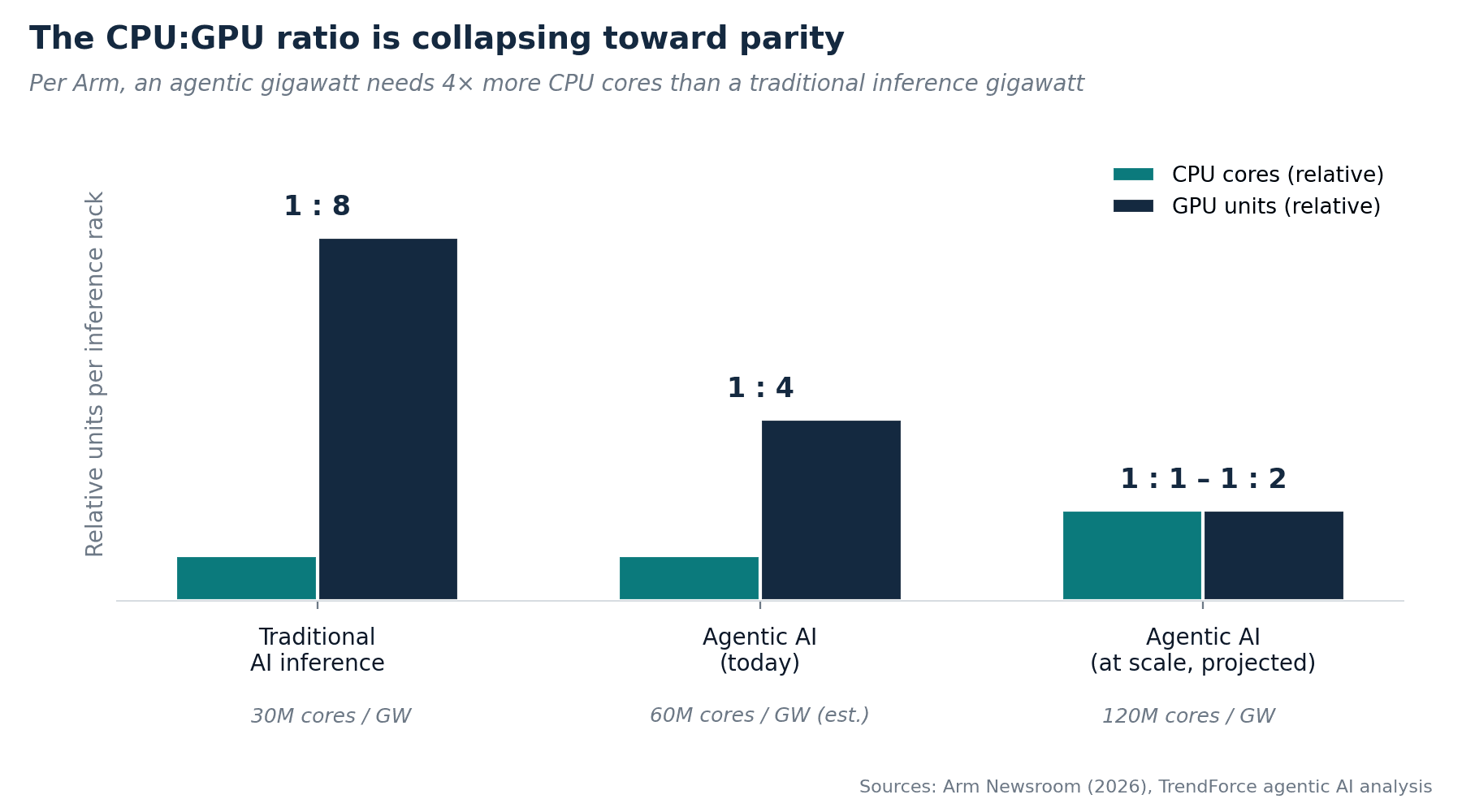
| 90.6% of an agent's time is spent on tools and orchestration — not on the model itself | 4× more CPU cores needed per agentic gigawatt vs. traditional AI inference (per Arm) | US$1.4B paid by Qualcomm for Nuvia in 24 months, pre-tape-out |
For the last few years, AI infrastructure has been told as a single tidy story: GPUs ate the world. Nvidia's market cap, the H100 allocation wars, the Blackwell roadmap, the rise of dedicated AI clouds, all of it reinforced a narrative in which the CPU was a legacy artifact. A tax on the rack. A commoditized substrate whose only job was to feed the accelerator and stay out of the way.
At 3C we have long been insisting that the story is far from the full picture, and that's why we were so early in inferencing chips. Another key argument that we have had for a long time was that the main user of AI won't be human, but AI itself, and this has massive investment implications. Yes, inferencing rise is one thing, but also, the very architecture of the data center also needs to change to accommodate an old friend of ours, the CPU. Think of an AI data center like a restaurant kitchen. For the last decade, the work was prep: massive, parallel, repetitive, chopping vegetables, prepping stock, baking bread. A GPU is a brilliant prep cook with 10 hands moving in parallel. But the work that's about to dominate the next decade isn't the actual cooking, but also plating, expediting, and running the pass, knowing what order goes where, handling the ticket queue, checking that the dish is right before it leaves the kitchen. That is what an agentic AI workload looks like. And nobody runs a kitchen pass with a prep cook. You need a sous chef: the CPU.
We believe the next decade of data-center economics will be shaped by who controls the host and "action" CPU as much as who controls the matrix-multiply silicon.
01The bottleneck has moved
The clearest signal that something has changed is what the engineers actually running production inference are now publishing about their own systems. They are not the people writing AI thinkpieces. They are the people the GPU pipeline is supposed to make happy. And they are reporting, with growing volume, that the GPU isn't the bottleneck anymore.
Three independent data points worth holding side by side:
| Source | What they found | What it means |
|---|---|---|
| vLLM project profiling (2025) | The HTTP API server consumes ~33% of total execution time on Llama 3 8B; CPU tokenization alone is up to 50% of inference latency under realistic load. | On a state-of-the-art GPU stack, half the wall-clock time was already not on the GPU. |
| LinkedIn SGLang deployment notes | Dominant share of end-to-end latency attributed to "CPU coordination and runtime behavior," not GPU compute. | Production deployments confirm what profiling suggested. |
| Blink: CPU-Free LLM Inference (arXiv 2604.07609) | SGLang, vLLM, and TensorRT-LLM retained only 28–54% of isolated throughput when run alongside modest CPU-side activity. | Current serving stacks lose roughly half their performance when the CPU is even mildly contended. |
The most arresting number, though, comes from a late-2025 paper that simply measured where realistic, tool-using agents, coding assistants, data agents, multi-step research workflows, actually spend their time. The answer (arXiv 2511.00739):
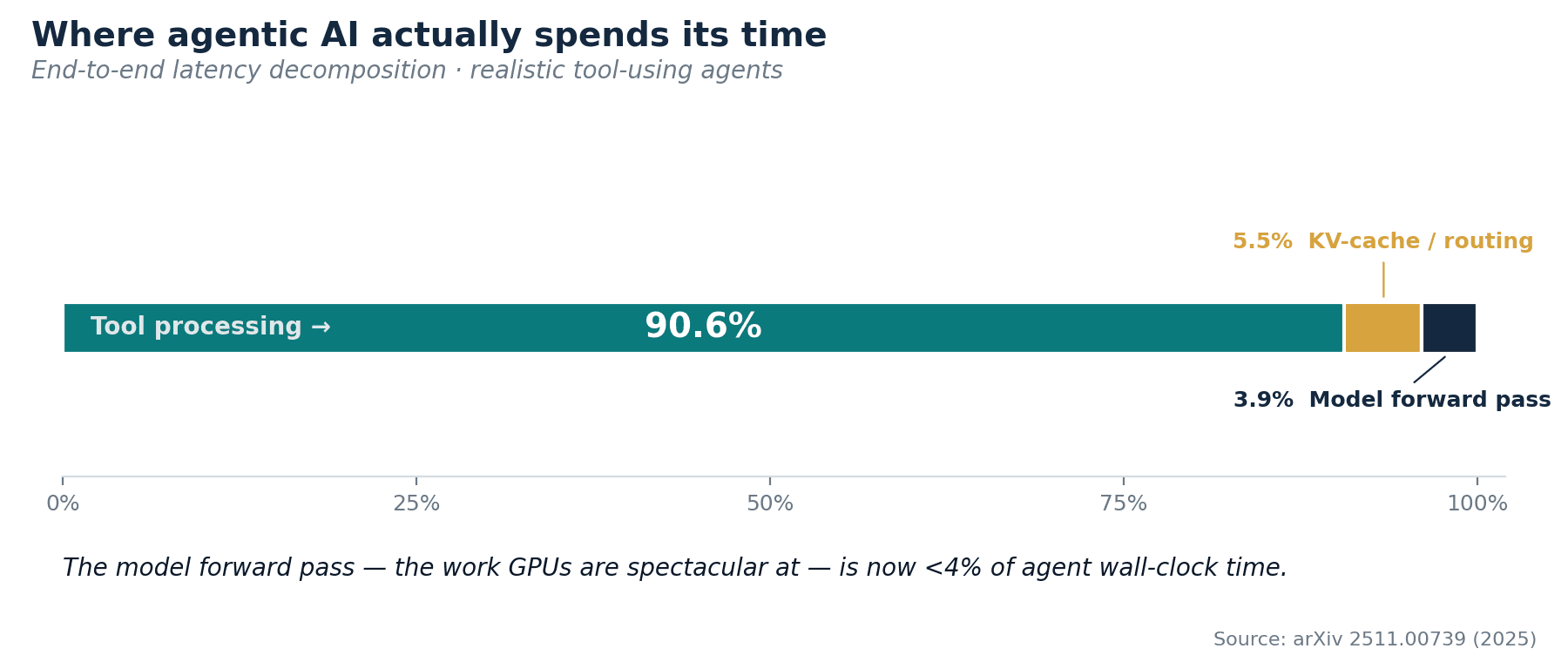
Tool processing is 90.6% of end-to-end latency. The model forward pass, the thing GPUs are spectacular at, is actually just under 4%.
Put differently, in a 10-second agent interaction, the GPU is doing real work for roughly 0.4 second. The other 9.6 seconds are JSON parsing, schema validation, API calls, code execution, memory lookups, retrieval, and the orchestration logic that decides what to do next. All of it runs on the CPU.
This is not a tuning problem. It is a category problem. As GPUs get faster with each generation, the CPU wrapper around them becomes proportionally more constraining. Buying faster GPUs without better CPUs is like widening a highway while leaving the on-ramps the same width. You pay for capacity you can't actually access.
02Agents are architecturally CPU-heavy
The reason the bottleneck moved is that the workload moved. A traditional inference call (prompt in, tokens out) is parallel, regular, and dominated by dense matrix multiplications. A GPU is the right answer. An agentic call is none of those things. It is irregular, branchy, control-flow-heavy, and full of stops to do something in the real world.
Six places the CPU does work the GPU genuinely cannot help with:
-
Tool orchestration. Every function call, API invocation, browser action, or shell command is a separate decision. Going back to the kitchen, think of it as the expediter calling tickets, what does this dish need next, and where does it go? That is the expediter's job at the pass, and it's the CPU's job in the rack.
-
Schema and JSON handling. Structured outputs, JSON-mode parsing, Pydantic validation, grammar-constrained decoding. Think of this as the line cook plating every dish exactly to the menu photo. Garnish in the right corner, sauce in the right quantity, etc. It is detailed, fiddly, error-checking work that lives entirely on the CPU. A coding agent can easily spend more time plating its output than cooking it.
-
Memory and retrieval. Vector search, KV-cache management, and context-window assembly are about finding the right ingredient, fast, from a very large pantry; the bottleneck is how quickly the line cook can reach the shelf, not how powerful the stove is. CPUs with high-bandwidth DDR5 and CXL-attached memory are the kitchens with a wide, well-organized walk-in right next to the line. GPUs, by contrast, have a tiny, very fast spice rack on the stove (think HBM), fantastic for what fits, useless for what doesn't.
-
Code execution and validation. Coding agents, by a wide margin the highest-value agentic workload today, must actually run the code they generate, in sandboxes, against test suites. Gordon Ramsay's favourite shout – taste everything before it gets out!
-
Multi-agent coordination. Once you have planner / executor / critic topologies, you have a kitchen with a head chef, sous chefs, and line cooks talking to each other in real time. The message bus is the call-and-response... "ordering!" "fire table seven!" "all day three steaks medium-rare!" The queueing and scheduling that keep that brigade synchronized are classic CPU work. Again, GPU can chop fast; it cannot run a brigade.
-
Tail-latency control. Diners don't remember the average wait. They remember the one time their entrée came out cold and late. Agents are the same, users feel p99, not p50. CPUs, with deterministic branch prediction and large caches, are the experienced line cook who rarely has a bad night: even when the kitchen is slammed and the orders are irregular, every plate goes out on time.
03The ISA wars are back!
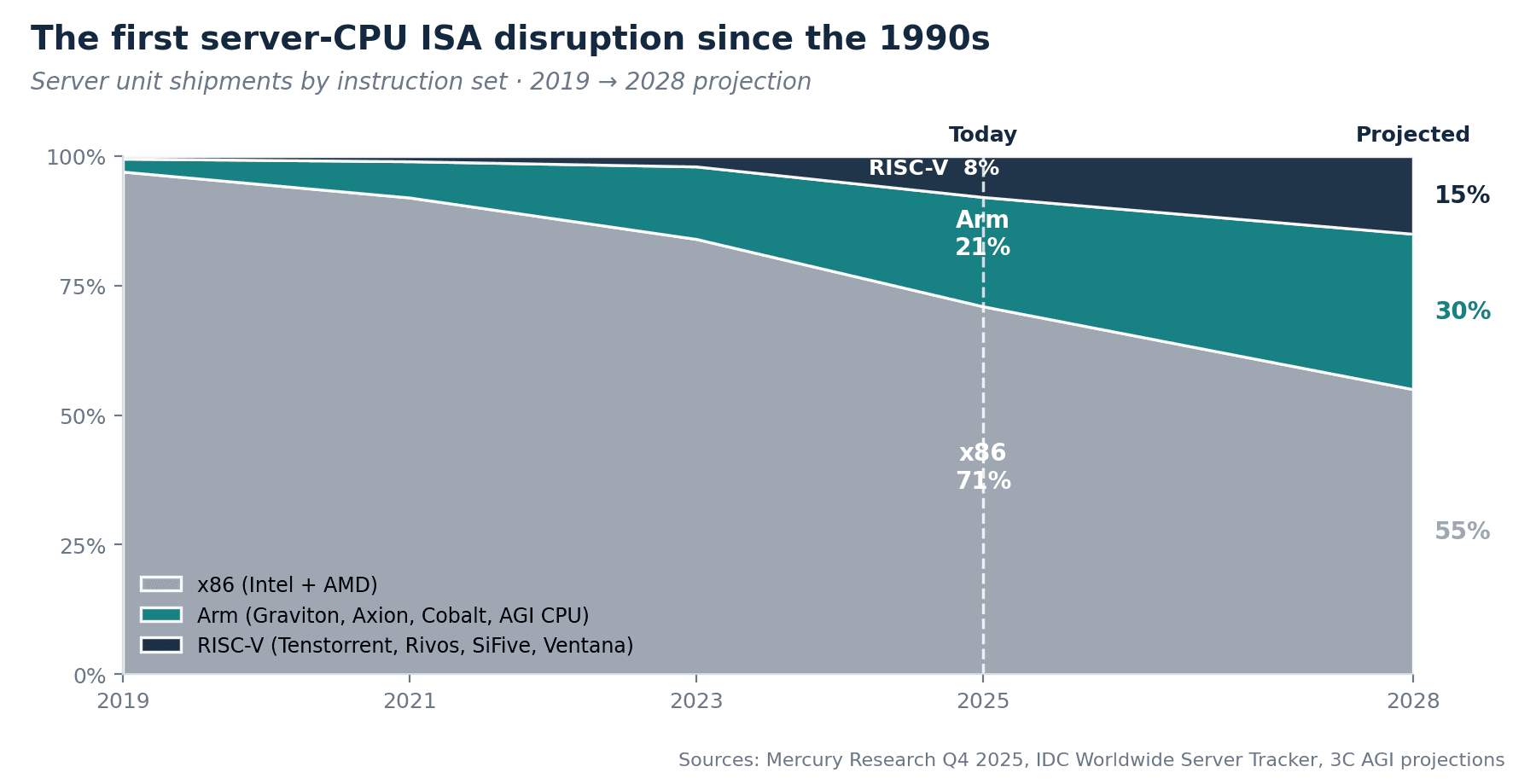
Behind all of this sits a deeper structural story: the server CPU market is undergoing its first genuine instruction-set disruption since the 1990s RISC wars, and the incumbents could lose ground if they don't move fast.
An instruction set (ISA) is, simply, the language a chip speaks. For 30 years the server-CPU market has effectively spoken one language, x86 (Intel and AMD). Now there are three serious contenders: x86, Arm, and RISC-V. The shift looks like this:
| ISA | Server share 2019 | Share 2025 | Projected 2028 | Who is building |
|---|---|---|---|---|
| x86 | 97% | 71% | ~55% | Intel, AMD (incumbents) |
| Arm | ~2% | 21% | ~30% | AWS Graviton, Google Axion, MS Cobalt, Arm AGI CPU, Nvidia Grace |
| RISC-V | less than 1% | ~8% | ~15% | Tenstorrent, Rivos, SiFive, Ventana |
The most consequential development, arguably, happened just this month. Arm itself crossed from licensing IP into direct silicon competition. The Arm AGI CPU (up to 136 Neoverse V3 cores, 800 GB/s memory bandwidth, native CXL 3.0, 96 PCIe Gen6 lanes, TSMC 3nm, with Meta as lead customer) places Arm in direct competition with its own largest licensees. OpenAI, Cerebras, Cloudflare, F5, SK Telecom, and Rebellions joined as early customers. Arm claims more than 2× perf-per-rack vs. x86 and up to $10B in capex savings per gigawatt of AI capacity.
This is also accelerating hyperscaler triangulation toward RISC-V to escape the Arm-as-vendor-competitor conflict that the AGI CPU created. This is good news for us as investors, more choice and more investable, actionable targets. SiFive, Tenstorrent, Rivos, to name a few.
Adding to all this is the importance of sovereignty. China's drive to reduce x86 dependency, Europe's Digital Sovereignty initiatives, and India's semiconductor programs all favor architecturally-open alternatives that cannot be export-controlled. Custom Arm and RISC-V are the only credible answers. For the first time since Itanium failed twenty years ago, the merchant CPU layer is genuinely contestable.
04Why this time is different: chiplets and CXL
Investors who remember the 2015–2018 "server-CPU renaissance" (yes we are that old!) Calxeda, AppliedMicro, Cavium, will reasonably ask what has structurally changed. At that time, Arm-based challengers promised to disrupt x86 incumbents but were ultimately constrained by capital intensity, ecosystem lock-in, and integration complexity. Two technological shifts meaningfully alter that equation today: chiplet-based design and CXL.
Chiplets as modularization of semiconductor design
Historically, a server CPU was implemented as a single monolithic die, often on the order of 600 mm², integrating cores, cache, memory controllers, and I/O. Such chips required multibillion-dollar programs and teams numbering in the hundreds. Yield risk scaled super-linearly with die area, and the integration burden sat entirely with the vendor.
Advanced packaging technologies (e.g., TSMC CoWoS-L, Intel EMIB) decouple that integration problem. Instead of fabricating one enormous die, designers now compose systems from smaller functional units, "chiplets", connected via high-bandwidth die-to-die interconnects. A startup can focus exclusively on the highest-value block: the compute complex. Memory controllers, PCIe, and other I/O functions can be licensed or sourced as pre-validated chiplets.
From an organizational perspective, this is profound. A 50-engineer team can now deliver a competitive 64-core compute chiplet, something that, in 2015, would have implied an order-of-magnitude larger team and budget. The technological shift is less about clever microarchitecture and more about architectural modularization enabled by packaging physics.
CXL and the redefinition of memory architecture
The second structural change is Compute Express Link (CXL), most recently formalized in its 4.0 specification in late 2025. CXL is a cache-coherent interconnect layered on PCIe that allows CPUs, accelerators, and memory expanders to share memory with hardware-enforced coherence semantics.
Earlier generations of server CPUs assumed relatively fixed, socket-local memory. CXL transforms memory into a composable, network-addressable resource. Version 4.0 doubles bandwidth to 128 GT/s over PCIe 7.0 and formalizes memory disaggregation at datacenter scale.
This matters particularly for emerging "agentic" AI workloads. Unlike traditional inference, which is often compute-bound and optimized around dense linear algebra on GPUs, agentic systems are frequently memory-bound, with irregular access patterns, large working sets, and dynamic state. Native CXL 3.0+ support allows CPUs to address memory pools that vastly exceed on-package HBM capacities, at lower cost per gigabyte, while preserving cache coherence. In effect, it restores architectural relevance to general-purpose CPUs in AI-centric infrastructure.
Venture implications
Translated into capital structure terms, these technical shifts compress the path to first silicon. What previously demanded US$1.5B+ in aggregate capex can plausibly be achieved in the US$300–500M range, largely because startups no longer shoulder full-stack SoC integration.
At the same time, the strategic acquisition floor appears unusually robust. Recent historical precedents, such as Annapurna Labs' acquisition by AWS and Nuvia's acquisition by Qualcomm, demonstrate that differentiated CPU IP can command substantial valuations even pre-tape-out provided it is strategically aligned.
On the demand side, hyperscalers, sovereign compute initiatives, and AI-native infrastructure providers all have strong incentives to diversify CPU supply and optimize for memory-centric workloads. The combination is economically unusual: reduced input cost, elevated exit floor, and unusually strong structural demand.
For 3C, that convergence defines a special window: the technological constraints that previously suppressed returns have materially shifted.
05The inference economics flip
Deloitte forecasts that inference will make up more than two-thirds of all AI compute by 2026, exceeding training. And the inference market is bifurcating into two profiles with very different chip economics:
| Workload profile | Example | Best chip | Why |
|---|---|---|---|
| Frontier model, batched inference | GPT-4-class, 70B+ models, high concurrency | GPU | Parallel decode dominates; HBM bandwidth matters most. |
| Sub-7B specialized models | Embeddings, rerankers, classifiers | CPU | Small models fit in DDR5; latency-sensitive, low concurrency. |
| Agentic orchestration | Coding agents, research agents | CPU | Branchy control flow + tool execution dominate. |
| Confidential inference | Regulated industries, sovereign AI | CPU | TEE / SGX / SEV; capabilities GPUs cannot easily match. |
The inference economics flip could be one of those underappreciated stories of 2026. It is the reason every hyperscaler is shipping a custom CPU, the reason SambaNova standardized on Xeon 6, the reason Intel Capital is writing checks into the inference layer, and the reason we believe the merchant CPU category is materially more investable in 2026 than at any point in the past twenty years.
06What this means strategically
We are not arguing that GPUs are unimportant. Frontier training is and will remain GPU-dominated. The argument is narrower: the layer of the AI stack that captures the most strategic value over the next decade is no longer guaranteed to be the matrix-multiply layer. The orchestration layer, the action CPU, sits between the model and the world. It runs the agent. It executes the tool. It validates the output. It controls latency. It controls cost. And it is, increasingly, the layer where the next generation of category-defining infrastructure companies will be built.
The narrative will catch up. It always does. By the time public-market analysts are writing about the "agentic CPU thesis," the most consequential rounds will already have been priced. We believe the window to take strategic positions in this layer is roughly 12–18 months wide, and that the operators and founders building inside it today are the ones who will own the next decade of inference infrastructure.